在上一篇文章 【降维分析】 声音的可视化探索:从鸟叫到声纹识别 中我们进行了声音可视化分析的初步探索,提出了能否用这种特性来进行语音识别的假设。下面我们就将完整走完整个语音聚类分析过程、操作方法与结果分析。
在研究材料上,我们不再麻烦亲友录制了,而是使用大型开源语言数据集。在全球大型语音语料库中,VoxCeleb1 是一个具有代表性的语音数据集,包含了来自全球范围的语音样本集。每个说话人身份信息标记得非常完整和清晰,为语音聚类分析提供了良好的基础。
一、语音数据聚类是什么?
语音数据聚类是一种无监督学习问题,其目标是通过语音特征,将语音数据视为“样本”,依据相似性将它们自动划分为若干簇(Cluster)。这些簇可能代表同一个说话人的声音分布。
在语音识别与语音数据研究领域,聚类技术可用于推测语音的来源,尤其是在没有明确标签信息的情况下,是一项非常实用的数据挖掘技术。我们选取 VoxCeleb1 数据集的一部分,尝试通过聚类分析找出说话人身份的分布边界,并探索声音是否具有“声音指纹”的特性。
二、语音特征提取:MFCC 与 Fbank
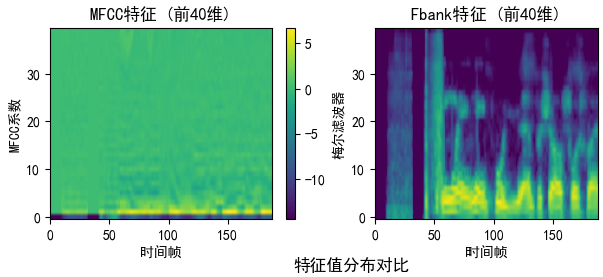
为了提出录音设备差异背景噪音干扰,更好地表征语音数据,我们使用了两种常用的音频特征:MFCC(梅尔频率倒谱系数)和 Fbank。
1. MFCC(梅尔频率倒谱系数)
- MFCC 是一种广泛用于语音分析的特征,通过计算语音的频谱能量分布并将其映射到梅尔频率尺度(近似人类听觉感知特性)。
- 每个 MFCC 特征向量包括 20 个主频段 + 两个差分(delta 和 delta2),总共形成 60 维的语音表征。
- 能够捕捉时间上的动态变化,是语音识别中常用的特征。
2. Fbank
- 与 MFCC 类似,但采用对数梅尔能量(Log-Mel Spectrogram)来表示语音的频谱特征。
- 更关注频段能量分布,包含了更多信息,对发音时间变化的捕捉不如 MFCC 灵敏。
针对说话人聚类任务结果:
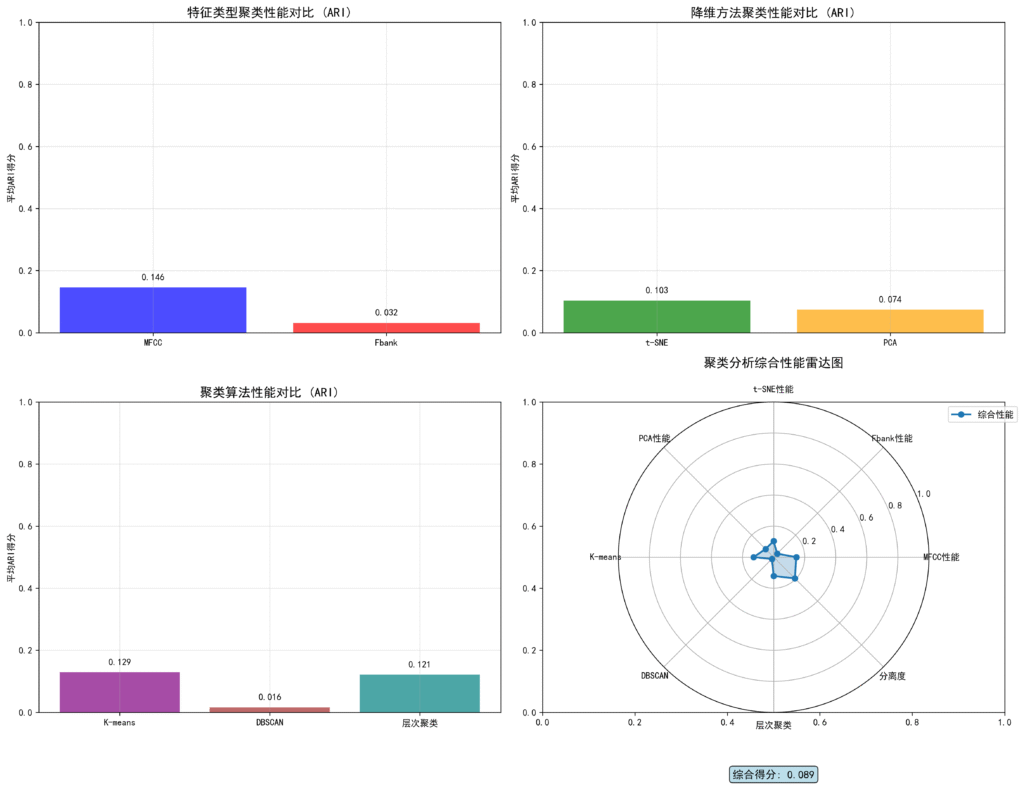
- MFCC 处理的平均 ARI 得分为 0.1459
- Fbank 处理的平均 ARI 得分为 0.0317
这表明:MFCC 更适合用于说话人聚类,推测它能更准确地表达语音的个性化特征。
三、降维方法:PCA 和 t-SNE
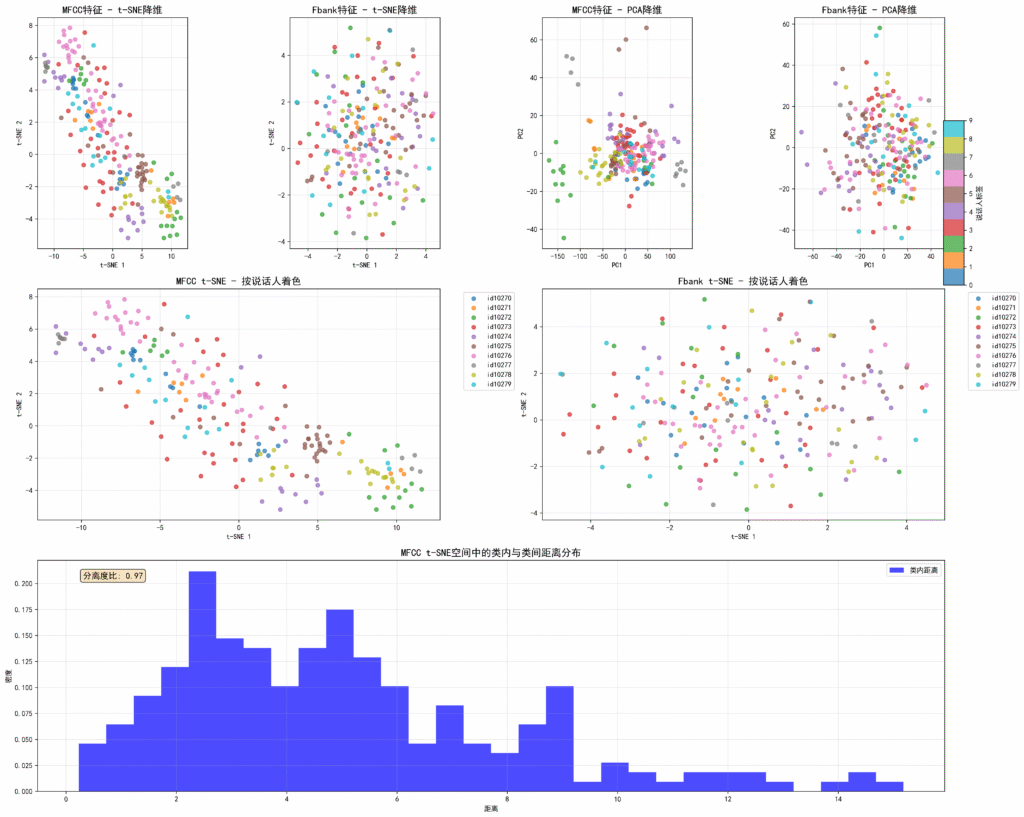
为了将高维语音特征(60 维)映射为可视化的 2D 结构,我们采用了两种经典的降维技术:PCA(主成分分析) 和 t-SNE(t-分布随机邻域嵌入)。
1. PCA(主成分分析)
- 是一种线性降维方法,通过最大化数据的方差来提取主要成分。
- 优点是运行速度快、可解释性好;缺点是可能丢失非线性结构信息,对复杂空间关系表达有限。
2. t-SNE(t-分布随机邻域嵌入)
- 是一种非线性降维方法,擅长保留高维数据的局部关系,适合可视化数据分布。
- 结果更贴近人类感知,对于不同说话人在高维空间中的分布关系更能体现出来。
针对说话人聚类任务结果:
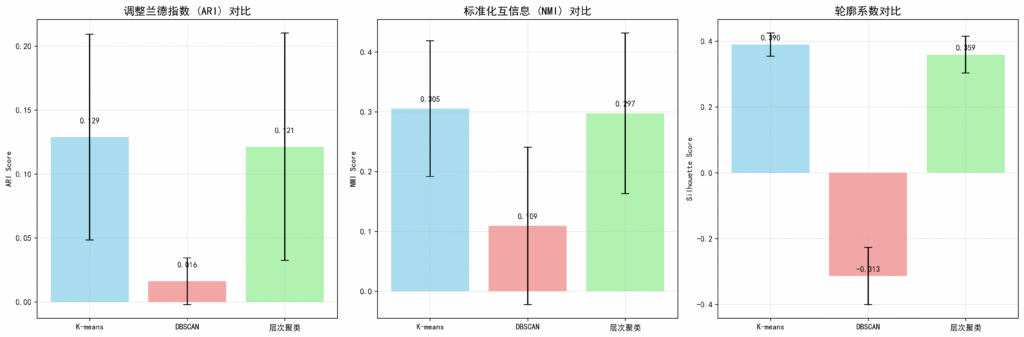
- t-SNE 处理的平均 ARI 得分为 0.1034
- PCA 处理的平均 ARI 得分为 0.0742
虽然结果表明:t-SNE 在保留语音特征分布细节方面表现更为出色,因而 ARI 和轮廓系数都更好。但从下图可以看出,其都没能呈现出明显的聚类,各类都混杂在了一起,只能期待其通过聚类算法能够有较好的表现。
四、聚类方法:KMeans、DBSCAN、层次聚类
为了评估语音数据的聚类效果,代码中运行了三种主流的聚类方法:KMeans、DBSCAN(密度聚类)和层次聚类。
1. KMeans 聚类
- 一种基于均值的聚类方法,将数据划分为若干个中心明确的簇。
- 在该实验中,我们选择了 10 个聚类簇,并基于真实标签评估了聚类效果。
关键结果:
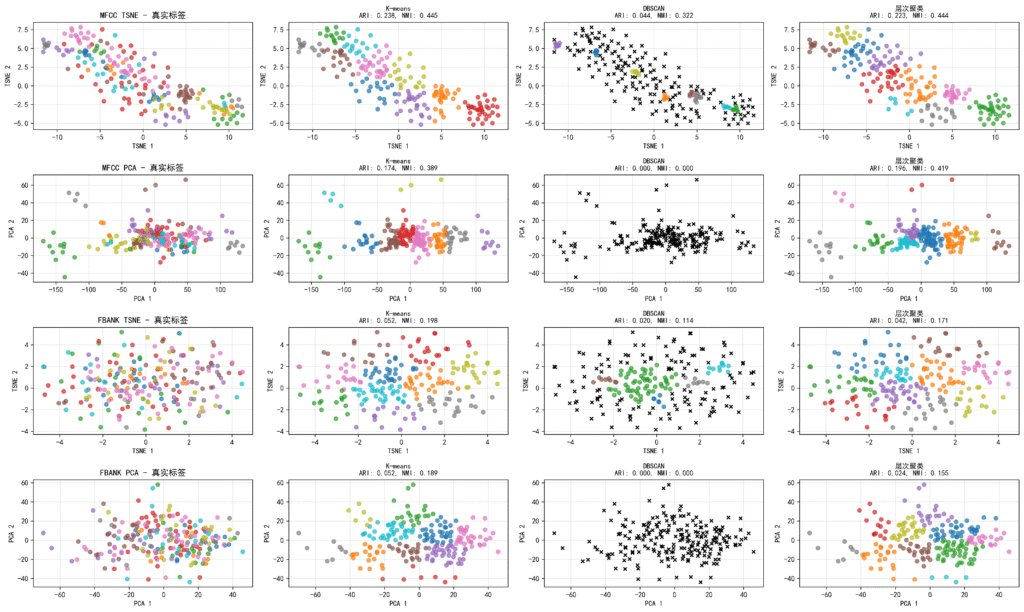
- 在 MFCC + t-SNE 空间下表现最佳,获得 ARI 得分 0.2384
- 聚类数 10,轮廓系数 0.4266
2. DBSCAN(密度聚类)
- DBSCAN 假设数据为不同密度的区域,自动识别噪声点。
- 举个例子就像在沙滩上寻找人群和孤立的个体,非常适合复杂、异构的数据集。
关键结果:
- 在 MFCC + t-SNE 下“拟合”出 8 个簇(ARI = 0.0445)
- 噪声占比高达 76.61%,说明语音数据存在较大的异质性和噪声干扰。
3. 层次聚类(Hierarchical Clustering)
- 通过构建树状结构(Dendrogram),揭示语音样本之间的层次关系,理解不同说话人、不同语音之间的关联。
关键结果:
- 在所有方法中表现不如下克莱斯的 KMeans
- 但轮廓系数良好(MFCC PCA 下为 0.432)
五、结果分析:为何 KMeans 在 MFCC t-SNE 下表现最佳?
从代码运行结果来看,MFCC + t-SNE 的组合下,KMeans 在语音聚类中表现最佳,其 ARI 得分高达 0.2384,意味着该方法在识别说话人之间聚类结构上具有一定的能力。
假设一:MFCC 更能捕捉声音的语义信息
- MFCC 更注重语音的频谱和时间动态变化,捕捉声学特征时比 Fbank 更贴近人对声音的感知机制。
- 因此,MFCC 更具代表性,能够更清晰地划分说话人边界。
假设二:t-SNE 在 MFCC 空间表现出更强的聚类分离能力
- t-SNE 通过非线性映射保留了不同说话人之间的分布关系,使得 KMeans 在 t-SNE 空间中的聚类边界更清晰、更优雅。
- 这也解释了为何 ARI 和轮廓系数在 t-SNE 空间下更高。
假设三:KMeans 在聚类中更稳健
- KMeans 能适配相对清晰的语音分布,尤其在 MFCC + t-SNE 的交织下能准确识别说话人身份。
- DBSCAN 在 t-SNE 空间下噪点占比较高(76.61%),说明语音数据混杂度较高,很多样本无法准确归类到某个说话人。
六、每个说话人的表现差异:纯度、同质性、完整性
以 KMeans + MFCC + t-SNE 为例,我们对每一位说话人的聚类效果进行了评估。
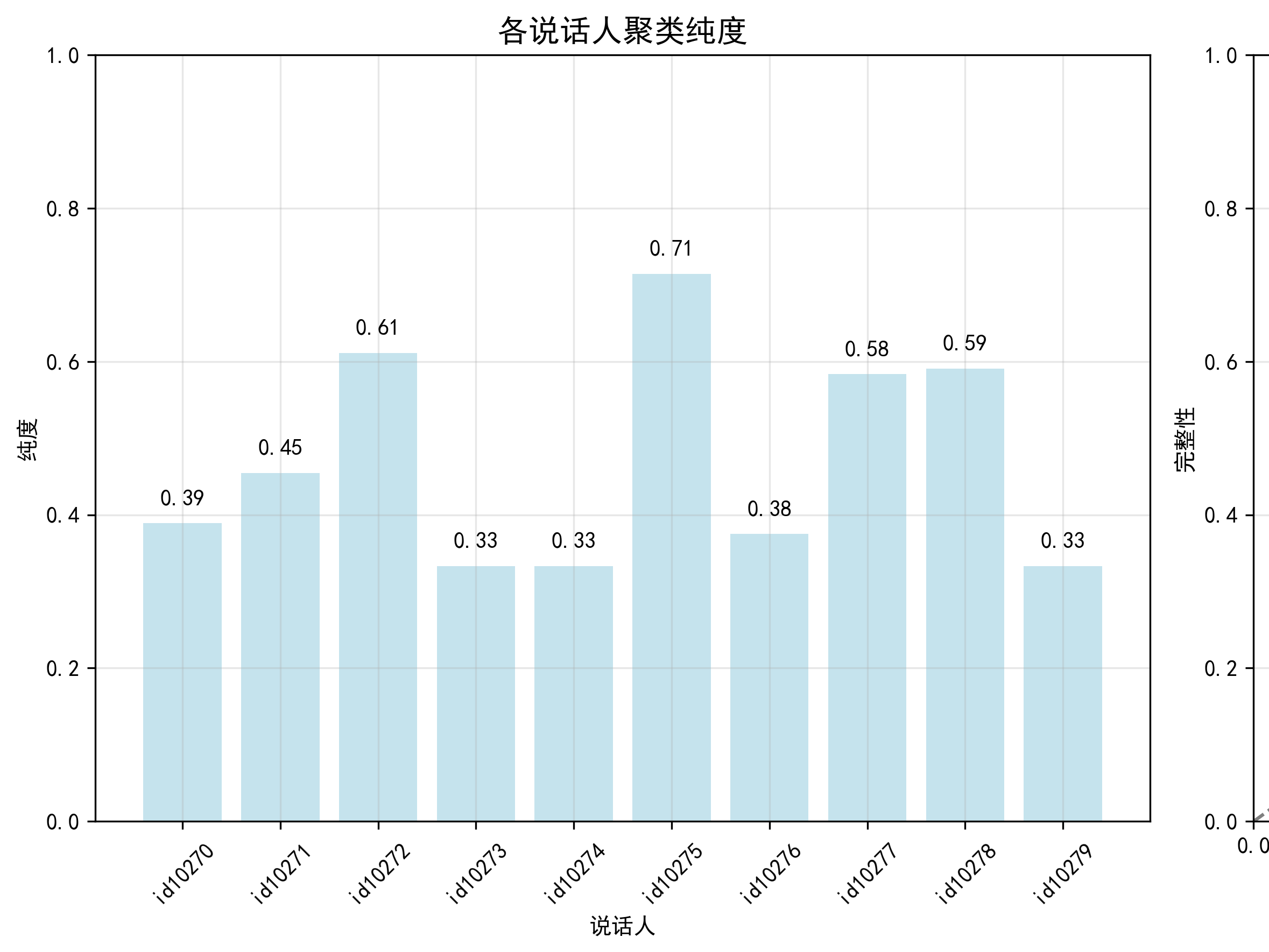
分析:
- 其纯度(Purity) 从中低(<0.3)到中高(>0.7)差异明显,反映不同说话人的语音差异程度不一,部分说话人更容易被识别。
- 除此之外,所有说话人分类结果的同质性(Homogeneity)均为 1,说明每个说话人的样本都被分到一个簇中,无跨说话人混淆。
- 除此之外,所有说话人分类结果的完整性(Completeness) 全为 0,表明未能完全划分所有说话人的语音,说明数据分布可能存在不均衡,或部分语音被错误地归到其他说话人下。
七、结果解读:语音聚类的问题与意义
1. 语音聚类效果非绝对,存在个体差异
- 语音聚类不是完全一针见血的识别任务。每个人的声音都独一无二,但某些人语音风格更显著,更容易在孟弗特空间中被分离。
- 聚类结果可能会受到发音习惯、语境、情绪等多种因素影响,导致某些说话人的语音分布较为模糊。
2. DBSCAN 擅长处理噪声,但也带来了“模糊”的问题
- DBSCAN 具有处理噪声点的能力,适合对语音数据进行初步筛查或重点关注真实样本。
- 然而,在本实验中,76% 的样本被判定为噪声,说明语音数据的一致性不足,配音、背景混音等情况可能导致聚类效果受损。
3. ARI 和 Silhouette 系数反映聚类能力的现状
- 尽管 KMeans 在 MFCC + t-SNE 空间中达成的最佳 ARI 得分为 0.2384,说明这个方法基本识别出某些说话人的聚类结构。
- 但由于语音样本之间的差异并非完全可区分,且数据可能包含混淆样本,因此聚类质量仍有提升空间。
八、语音可视化:图像蕴含的声音边界
从代码跑出的可视化图表我们不难发现,即便采用 MFCC + t-SNE 技术,语音数据中的不同说话人仍然存在较大重叠区域,说明:
| 项目 | 说明 |
|---|---|
| 最佳聚类配置 | mfcc_tsne_kmeans(0.2384 ARI) |
| 语音特征 | MFCC 更具代表性,能准确捕捉说话人音色特征 |
| 降维方式 | t-SNE 优于 PCA,保留了更好的簇间关系 |
| 聚类算法 | KMeans 是最稳健的选择,层次聚类和 DBSCAN 存在噪声干扰 |
| 噪声比例 | 一些方法(如 DBSCAN)发现超过 70% 的样本为噪声 |
| 整体分离度(Separation Ratio) | 仅 0.97,分离度良好但仍有提升空间 |
九、未来优化方向
- 使用深度学习特征:如 CNN、DNN 或预训练语音模型(如 VGGish)提取的嵌入特征,可能更接近人类听觉的感知方式。
- 优化降维参数:t-SNE 的参数选择对结果影响显著,可以通过调优保留更多的结构信息。
- 增加样本量:每位说话人仅使用了少量语音片段,数据稀疏可能影响聚类效果。
- 调整算法超参数:如 KMeans 的簇数、DBSCAN 的
eps和min_samples等参数,需要根据实际数据分布进行优化。