
【聚类分析】降维聚类判断是谁在说话
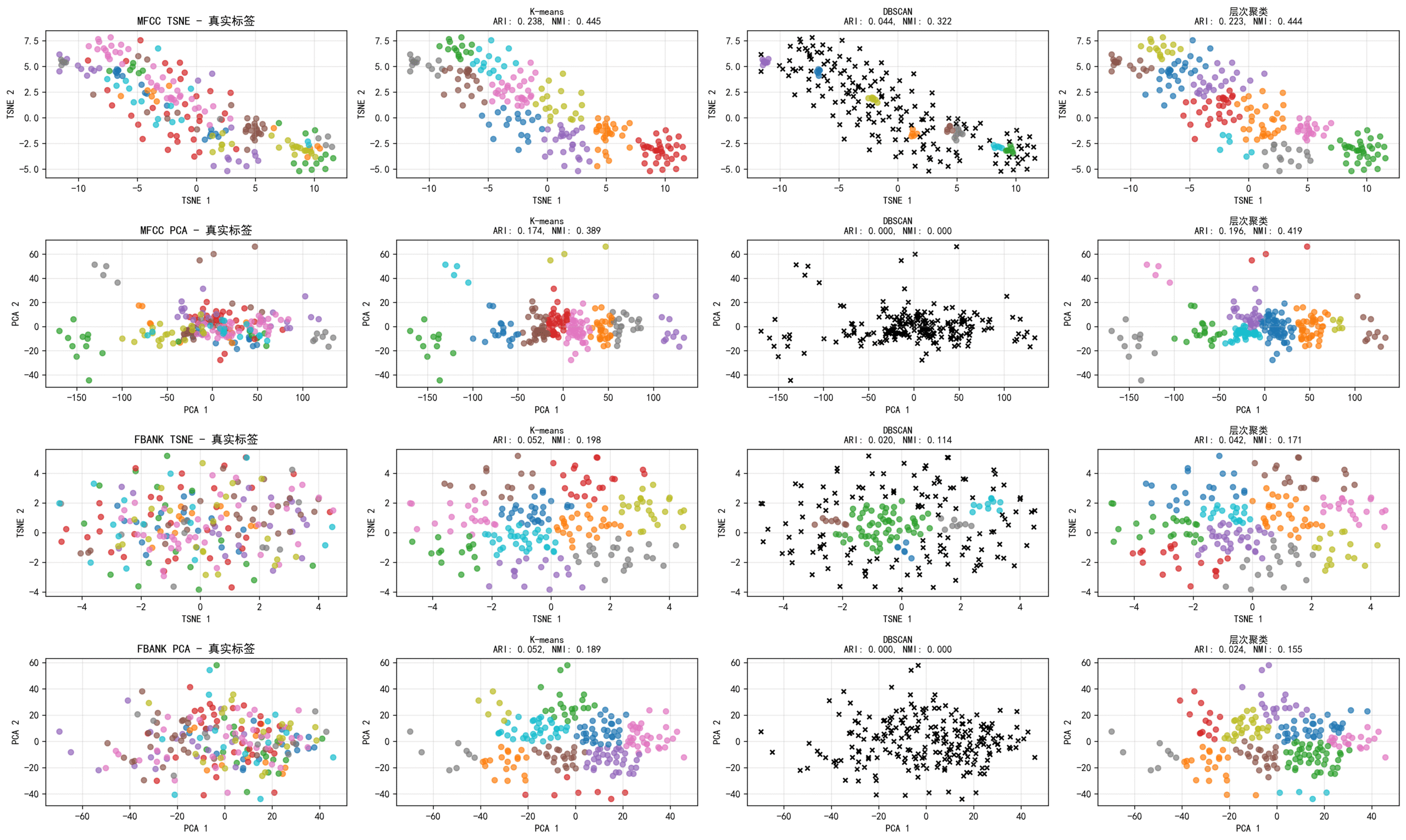
本文基于 VoxCeleb1 语音数据集,探索了通过语音特征提取与聚类分析来识别说话人身份的可行性。文章首先介绍了语音数据的聚类任务及其意义,并对比了两种常见的语音特征——MFCC 和 Fbank,指出 MFCC 更具代表性。随后,探讨了降维方法 PCA 和 t-SNE 的应用场景与效果,认为 t-SNE 在保留语音结构方面更优。接着,对三种主流聚类方法(KMeans、DBSCAN、层次聚类)进行了评估,发现 KMeans 在 MFCC + t-SNE 组合下聚类效果最佳,并提供了相应的数据支持。此外,文章还分析了每个说话人语音在聚类中的表现差异,揭示语音聚类并非绝对精准,而是受特征、样本量、噪声等因素影响。最后提出了未来改进的方向,如使用深度学习特征、优化降维参数、增加样本量等,以为进一步提升语音聚类的效果和实用性。