知乎上有人提问:
特征选择若使用包裹式或嵌入式都得基于预测模型,那么这时候是先用模型的默认超参数做特征选择吗?然后再用新特征集进行超参数寻优?那这样会不会出现一个问题,就是使用默认参数时并没有充分发挥所有特征的信息,导致一些有用的特征被筛掉了,导致整体性能变差,再怎么优化超参数也没用了。
本篇是对其问题的回答,也是对于此前【监督学习】:说话人特征提取算法比较 – Under the Sun with Paddy实验的回顾和总结。
是的,使用默认参数时很容易没有充分发挥所有特征的信息。解决方法是:应该将特征选择本身视为模型训练一个需要优化的“超参数”。
建议
- 理解模型的“偏好”:首先通过文献和经验,定性分析你的模型擅长处理何种信息(空间、时间、频率…),再据此设计或选择特征。
- 将特征子集作为超参数:在计算资源允许时,最严谨的方法是将“使用哪组特征”本身作为一个超参数,与模型参数一同进行优化。
- 优先使用嵌入式选择:使用L1正则化、树模型等内置特征重要性评估的方法,让特征选择与模型训练同步进行。
- 谨慎进行特征扩展:任何新的特征扩展(如我的动态特征)都应以控制变量的方式进行严格评估,警惕“维度堆砌”的陷阱。
具体的分析和结论
在我之前的实验中,我比较了MFCC、Fbank和LPCC三种音频特征在说话人识别任务中的表现。实验设计类似于一种“特征选择”场景:我固定了CNN模型的架构,比较MFCC、Fbank和LPCC三种音频特集性能。
实验发现:
1,特征集本身对性能有决定性影响。对于相同模型的多次实验中,MFCC在低噪声下准求率就底的降无可将。没有好的食材,厨艺在精湛也没用,再参数调优也提高不了鲁棒性。
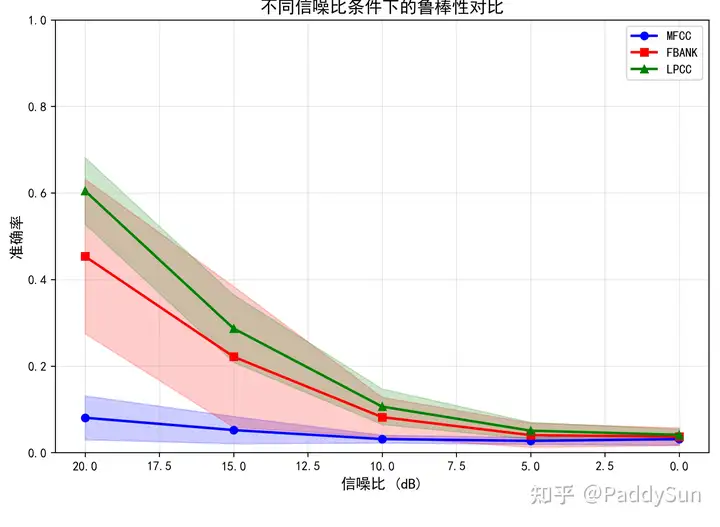
2,不同特征集在不同模型下性能差异显著。
我使用CNN模型结果是:LPCC ≈ Fbank > MFCC;使用LSTM模型的文献结果是:Fbank > MFCC > LPCC,这说明了特征和使用什么模型超参数是紧密耦合的。如果先用默认超参数做特征选择,可能会过早地丢弃一些有用特征(如LPCC,其在文献中普遍不被看好),因为默认参数无法充分发挥这些特征的潜力,从而导致整体性能上限降低。
3,不合时宜的特征会破坏模型原有的学习能力。
预实验时,我‘自作聪明’地将FBank与其一阶、二阶差分动态特征拼接在一起,结果FBank特征的准确率急剧下降。特征工程的关键在于‘适配’而非‘堆砌’。为LSTM提供丰富的时序动态特征是‘投其所好’,而为CNN提供同样的特征则是‘强人所难’。在机器学习中,理解你的模型‘喜欢吃什么’,比一味地提供‘昂贵的食材’要重要得多。”
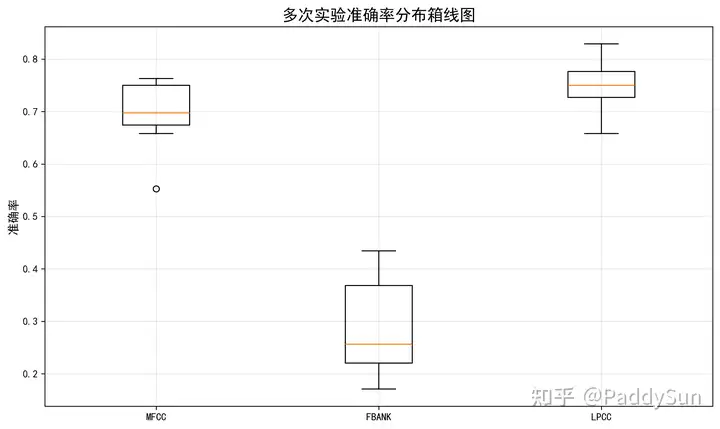
结论和启示
1,“特征-模型协同设计“
传统的机器学习流程常将特征工程与模型训练视为两个独立的阶段,但我的实验表明这存在严重局限。更有效的做法是建立协同设计的思维:
在前向设计时:根据任务特性先预设可能的有效特征,同时考虑匹配的模型架构。比如处理时序依赖强的任务,优先考虑LSTM/Transformer与动态特征的组合;处理局部模式明显的任务,则考虑CNN与静态特征的搭配。
在反向验证时:当模型表现不佳时,不仅要调整超参数,更要反思特征集与模型的匹配度。我的FBank+动态特征实验就是典型案例——性能下降时首先应该质疑的是“这些特征吗真的适合这个模型嘛”,而不是盲目继续调参。
2. 采用分阶段-迭代式的特征评估策略
针对“默认参数做特征选择可能误删有用特征”的困境,我建议:
第一阶段:广度探索
使用简单模型(如SVM、浅层CNN)和默认参数快速测试各个特征集的潜力上限,重点关注不同特征集带来的性能差异趋势,而不是绝对数值。此时的目标是识别出有前途的特征方向,而不是做出最终选择。
第二阶段:深度优化
对潜力特征集,进行特征子集+模型超参数的联合优化。例如使用贝叶斯优化同时搜索特征组合和关键超参数。这一阶段的计算成本虽高,但能避免因前期草率特征选择导致的性能天花板。
第三阶段:交叉验证
最有说服力的做法是在多个不同架构的模型上验证特征集的有效性。如果一个特征集在CNN、LSTM、Transformer等多种模型下都表现良好,那它很可能确实包含了任务的本质信息。
3. 理解不同模型的“特征偏好”先验
从我的实验和阅读论文,可以提炼出一些模型偏好的经验法则:
CNN类模型:偏好局部相关性强的特征,如图像中的相邻像素、音频中的相邻频带。特征应该尽可能保留空间结构信息。
LSTM/RNN类模型:偏好具有清晰时间演变的特征,对特征的平滑性和动态范围相对不敏感。
这些先验知识可以在实验初期为我们提供有价值的指导。
写的不错