引言:从无监督到监督
在之前我们实验了无监督的聚类方法(kmeans,DBSCAN,层次聚类),表现最好方案 mfcc特征提取+tSNE降维+kmeans聚类,效果很差。
mfcc特征提取+tSNE降维+kmeans聚:
具体来说,虽然其整体分离度(Separation Ratio)能够达到0.97,这表明聚类结果的簇内距离相对较小,簇间距离相对较大,聚类质量很高,解释了一些声音的结构特征;但其调整兰德指数(ARI)也仅为0.2384,意味着聚类结果与真实标签之间的匹配程度较低。
为了更好的完成说话人识别任务我进行了粗浅的论文阅读,通过阅读论文(随便看了几篇,大部分是近代而非现代的啦),总结说话人分类技术发展历程如下。
| 发展阶段 | 时间范围 | 特征提取技术 | 分类算法 | 主要特点 |
|---|---|---|---|---|
| 传统方法阶段 | 20世纪80-90年代 | • LPCC(线性预测倒谱系数) • MFCC(梅尔频率倒谱系数) • 反射系数 • 面积函数 • 对数面积比 | • 矢量量化(VQ) • 模板匹配法 • 最小距离分类器 • 高斯混合模型(GMM) | • 基于声道模型和听觉特性 • 手工设计特征参数 • 识别率相对较低 |
| 统计模型发展阶段 | 2000-2010年 | • 差分倒谱参数 • 特征加权 • 瓶颈特征(BN) • 说话人编码 | • GMM-UBM框架 • 隐马尔可夫模型(HMM) • 支持向量机(SVM) • 因子分析(JFA) | • 引入通用背景模型 • 统计建模方法成熟 • 文本无关识别成为主流 |
| 深度学习革命阶段 | 2010年 | • FBank特征 • X-vector • d-vector • 深度特征 • 端到端特征 | • 深度神经网络(DNN)• 卷积神经网络(CNN) • 循环神经网络(RNN/LSTM) • 注意力机制 • 生成对抗网络(GAN) • 端到端模型(CTC) | • 自动学习特征表示 • 端到端建模 • 性能大幅提升 • 处理复杂场景能力强 |
看完论文,我决定试试炼丹(采用基于深度学习的端到端方法),这是亲爱的Deep Seek给我的理由:
- 理论依据:深度学习使用多层的非线性结构将低层特征变换成更加抽象的高层特征,相比传统浅层模型拥有更强的表达和建模能力。语音信号作为一种非平稳的随机信号,其形成和感知过程本身就是一种复杂信号的处理过程,深层模型在一定程度上能够模拟人类语音信息的结构化提取过程[1]。
- 性能优势:自2009年深度学习首次应用于语音识别任务以来,相比传统的高斯混合模型-隐马尔科夫模型(GMM-HMM)语音识别系统获得了超过20%的相对性能提升[1]。深度学习方法在复杂信号处理上展现出明显优势。
- 技术成熟度:近年来,基于深度学习的说话人识别技术取得了突破性进展,如X-vector、d-vector等深度特征提取方法,以及端到端建模技术,都显著提升了识别性能[3]。
机器学习什么的太复杂了(我太菜了),我们还是先比较三种主流音频特征提取算法(MFCC、LPCC、深度特征)在说话人识别任务中的表现,系统评估其在准确性、鲁棒性等方面的性能差异。
三大音频特征的”武功秘籍”
MFCC:语音识别的”老将”
MFCC(梅尔频率倒谱系数) 可以说是语音处理领域的”常青树”,从零几到近些年的论文中其都频繁出现,在我们先前无监督的学习中也表现出色。它的设计灵感来源于人类听觉系统——我们耳朵对不同频率声音的敏感度是不同的。
工作原理简析:
- 模拟人耳:通过梅尔尺度模拟人耳的非线性频率感知
- 倒谱分析:分离声源特征和声道特征
- 动态特征:捕捉语音的时序变化
LPCC:基于物理模型的”理论派”
LPCC(线性预测倒谱系数) 走的是另一条技术路线。它基于语音产生的物理模型,试图通过数学方法描述我们的发声器官。查阅到的多篇论文中其表现都逊于MFCC,但还是请出来试试身手。
理论基础:
- 线性预测:用过去的语音样本预测未来的样本
- 声道建模:模拟口腔、鼻腔等共振腔的滤波特性
- 参数精简:用少量参数描述复杂的语音信号
Fbank:深度学习的”新宠”
Fbank(滤波器组能量) 可以看作是MFCC的”前身”。它保留了梅尔滤波器组的能量信息,但没有进行最后的倒谱变换。但在我们先前无监督的学习中也表现较差(MFCC 处理的平均 ARI 得分为 0.1459,Fbank 处理的平均 ARI 得分为 0.0317)。
独特优势:
- 信息保留更完整:避免了倒谱变换可能的信息损失
- 更适合深度学习:让神经网络自己学习有用的特征组合
- 计算更简单:少了一步DCT变换
实验设计:公平的竞技场
参考崔琳等人对于特征提取效果研究的实验设计[5],设计了”严谨”的实验方案。并且预实验时发现CNN的表现有着很高的随机性(可能这就是被称为炼丹的原因),研究的是特征处理,所以不固定随机数种子,训练重复十次。
数据准备
因为电脑空间有限,装不下20多G的完整VoxCeleb1训练集,加上需要克服CNN训练中的随机性,进行重复实验大量数据对于训练时间变得很长很长,所以只下载了VoxCeleb1测试集部分。
| 音频时长统计 | 数据集 |
|---|---|
| 时长标准差: 7.56 秒 | 说话人数量:40人 |
| 最短时长: 4.00 秒 | 训练集:668个样本 |
| 最长时间: 24.16 秒 | 验证集:143个样本 |
| 平均时长: 7.13 秒 | 测试集:144个样本 |
数据预处理时,统一设置如下参数:
- 采样率:16kHz
- 帧长:25ms
- 帧移:10ms
- FFT大小:1024
CNN模型架构
采用统一的经典卷积神经网络架构。模型包含多个卷积层、批归一化、Dropout等现代深度学习组件。
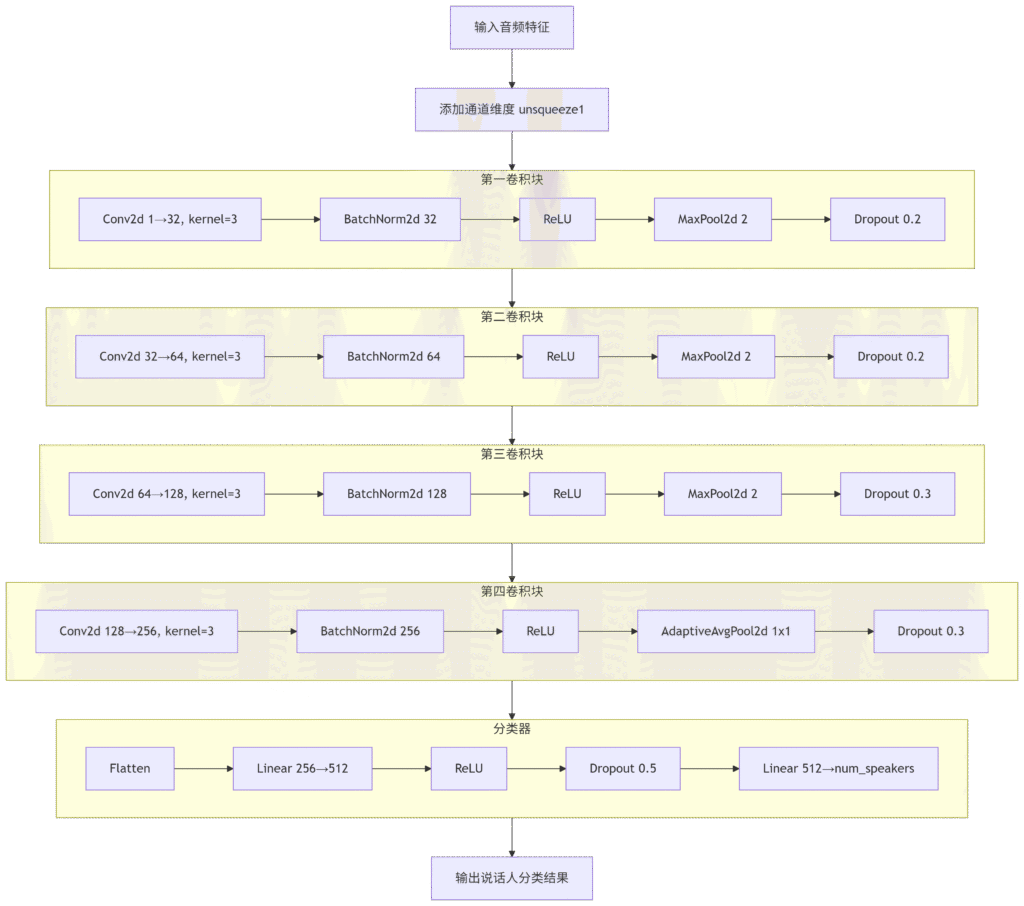
特征提取设计
主要参考崔琳等人的研究成功,选择各自特征提取方法的最佳参数。
特征提取流程步骤
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | 音频加载与分割 | 使用librosa加载,按3秒分割 |
| 2 | 预加重处理 | 仅LPCC使用,系数0.97 |
| 3 | 分帧加窗 | 汉明窗,25ms帧长,10ms帧移 |
| 4 | 特征提取 | 分别计算MFCC/Fbank/LPCC |
| 5 | 动态特征计算 | MFCC和LPCC添加一阶、二阶差分 |
| 6 | 特征标准化 | 均值方差归一化 |
| 7 | 特征堆叠 | 时间帧×特征维度 |
特征提取参数设置
| 特征类型 | 参数名称 | 参数值 | 计算方法/说明 | 设置的原因 |
|---|---|---|---|---|
| 通用参数 | 采样率 | 16000 Hz | 音频重采样率 | |
| 帧长 | 25 ms | FRAME_LENGTH | 语音信号的短时平稳特性,通常选择20-30ms以保证信号在帧内平稳[7] | |
| 帧移 | 10 ms | FRAME_SHIFT | 保证相邻帧之间有足够的重叠,避免帧间变化过大,通常为帧长的1/2-1/3[7] | |
| FFT点数 | 512 | N_FFT | 在16kHz采样率下,512点FFT提供足够的频率分辨率,同时计算效率较高[6] | |
| 音频片段长度 | 3.0 s | segment_length | 基于数据集的统计信息 | |
| MFCC特征 | MFCC系数 | 13维 | n_mfcc=13 | 低阶倒谱系数能够反映声道的脉冲响应特征,13维是说话人识别的常用维度[5] |
| 梅尔滤波器数 | 40个 | n_mels=40 | Mel滤波器组在低频区域分布密集,能够更好地模拟人耳听觉特性[4] | |
| 动态特征 | 一阶、二阶差分 | 共39维特征(13+13+13) | 反映语音的动态特性,人耳对动态特性更为敏感,能显著提高识别率[5] | |
| 标准化 | 均值方差归一化 | (x-μ)/σ | ||
| Fbank特征 | 梅尔滤波器数 | 40个 | n_mels=40 | 测试时发现对Fbank也组合上1,2阶差分其效果明显下降,古没有组合同台特征 |
| 特征维度 | 40维 | 对数梅尔频谱能量 | ||
| 动态特征 | 无 | 仅使用静态特征 | ||
| 标准化 | 均值方差归一化 | (x-μ)/σ | ||
| LPCC特征 | LPC阶数 | 12阶 | order=12 | 对于语音信号,12阶LPC能够较好地模拟声道特性,是常用选择[5] |
| LPCC系数 | 12维 | n_ceps=12 | ||
| 预加重系数 | 0.97 | 高频增强 | 补偿语音信号被抑制的高频部分,消除声带和嘴唇效应,提升高频信号[9] | |
| 动态特征 | 一阶、二阶差分 | 共36维特征(12+12+12) | 反映语音的动态特性,人耳对动态特性更为敏感,能显著提高识别率[5] | |
| 标准化 | 均值方差归一化 | (x-μ)/σ |
我个人猜测于认为:
- Fbank可能在深度学习框架下略胜一筹
- MFCC作为基准应该会有稳定表现
- LPCC可能表现最差
结果分析
在完成十次重复实验后,我们得到了三种特征提取方法在说话人识别任务中的综合表现数据。本部分将从整体性能比较和具体性能评估两个维度进行分析,并结合特征本身的特性对结果进行推测性解释。
比较分析:三种特征的”华山论剑”
从整体识别性能来看,三种特征提取方法在说话人的准确率相差不大,MFCC表现略逊一筹。
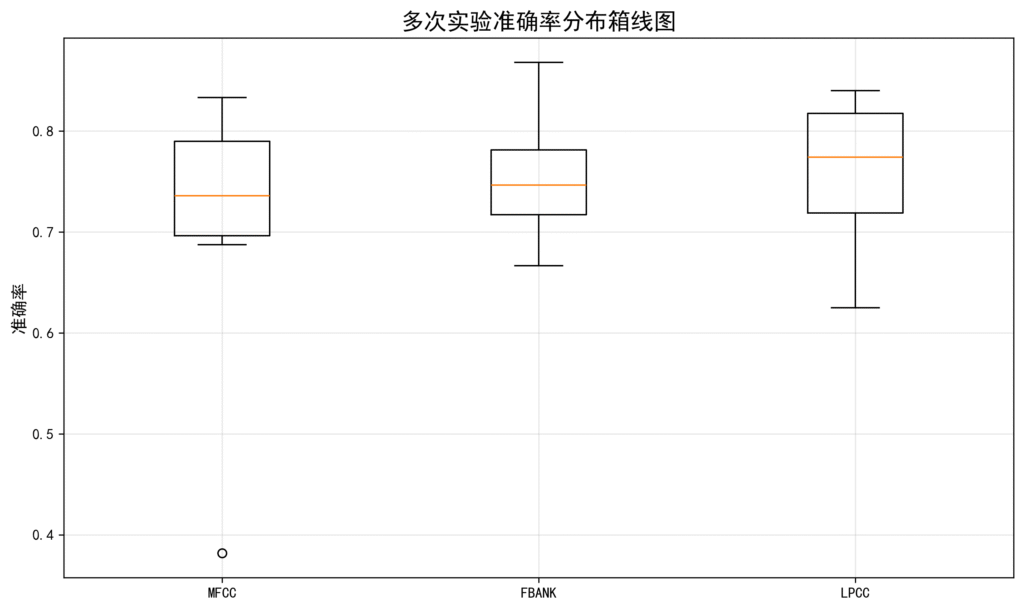
准确率与F1分数表现:
在40说话人数据集上,LPCC表现出最高的准确率(76.11%准确率,75.31%F1),Fbank次之(75.07%准确率,73.59% F1),MFCC相对较低(71.53%准确率,69.95% F1)
在20说话人简化数据集上,Fbank实现最佳性能(78.42%准确率,77.94% F1),LPCC紧随其后(76.71%准确率,75.73% F1),MFCC仍居末位(74.74%准确率,73.51% F1)
这一结果部分颠覆了我最初的预期——LPCC这个”理论派”在实际表现中并不逊色,甚至在复杂场景下略胜一筹。而Fbank在数据量减少时展现出更好的适应性,MFCC则始终保持着稳定但非最优的表现。
性能稳定性分析: 通过十次重复实验的标准差来看,Fbank在40说话人数据集上展现出最佳的稳定性(准确率标准差5.55%),LPCC在20说话人数据集上最为稳定(准确率标准差5.13%)。MFCC在两个数据集上都表现出较大的波动性(标准差分别达12.15%和8.94%),说明其性能受训练随机性影响较大。
从CNN训练的收敛速度来看LPCC在20说话人数据集上训练时间标准差最小(41.35秒),表明其收敛过程相对稳定;而MFCC在40说话人数据集上训练时间标准差较大(138.88秒),说明收敛过程存在较大波动印证了其性能受训练随机性影响较大。
鲁棒表现
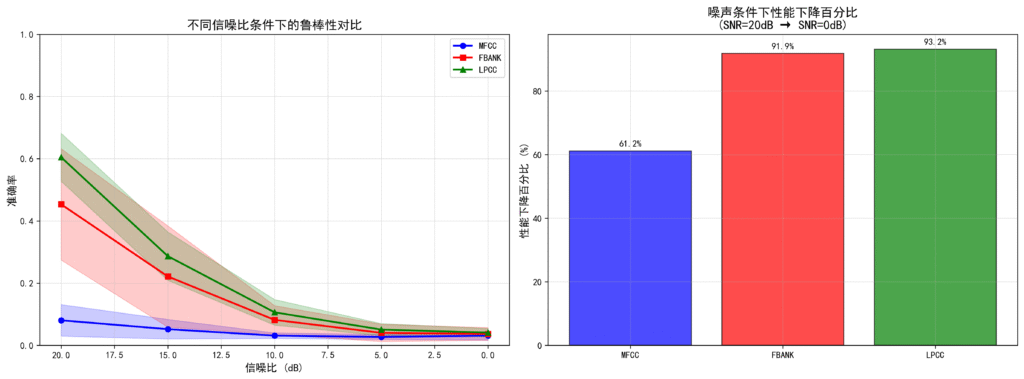
在噪声环境下的测试结果中,LPCC与Fbank特征的鲁棒性同样相差不大。
LPCC在噪声条件下表现最佳,在40说话人数据集上噪声下准确率达21.79%,在20说话人数据集上达24.82%
Fbank噪声鲁棒性次之,相应准确率为16.68%和29.32%
MFCC对噪声最为敏感,噪声下准确率仅4.44%和9.89%
噪声下性能保持率(SNR=0dB时的性能占SNR=20dB的比例)进一步证实了这一趋势:MFCC在40说话人数据集上保持率最高(38.79%),但在实际准确率绝对值上仍远低于其他两种特征。
结果推测:为什么”理论派”逆袭了?
基于以上结果,亲爱的Deepseek对三种特征的表现差异进行如下推测:
- LPCC的意外优势:
- 物理模型的基础:LPCC基于语音产生的物理模型,可能更好地捕捉了说话人生理特征(如声道形状),这些特征在噪声环境下相对稳定
- 参数精简效应:12维LPCC系数相比其他特征的更高维度,可能减少了过拟合风险,特别是在数据量有限的情况下
- 预加重处理:LPCC特有的预加重步骤增强了高频信息,可能在噪声环境中提供了更多鲁棒性特征
- Fbank的深度学习适配性:
- 信息保留完整:Fbank避免了MFCC的DCT变换信息损失,为CNN提供了更丰富的原始特征,让网络自行学习最佳表示
- 维度适中:40维特征在表达能力和计算复杂度间取得良好平衡
- 数据量依赖性:在20说话人简化数据集上Fbank表现最佳,说明其在数据量减少时仍能保持较好性能
- MFCC的相对劣势:
- 倒谱变换的副作用:MFCC的倒谱分析在分离声源和声道特征时,可能丢失了对说话人识别有用的混合信息
- 噪声敏感性:基于人耳听觉特性的Mel尺度在噪声环境下可能放大失真效应
- 动态特征的局限性:虽然添加了一阶二阶差分,但在深度学习框架下,这些手工设计的动态特征可能不如网络自行学习有效
思考与启示
本次实验给我最大的启示是:在深度学习时代,传统特征提取方法仍然有其价值。LPCC这个基于上世纪七八十年代理论的方法,在特定场景下竟然能与现代方法一较高下,这提醒我们不应盲目追求”最新最好”,而应基于具体任务和数据特性选择合适的技术。
值得一提的是,特征提取时间虽在实验环境中差异明显,但在实际应用中,LPCC的0.1秒提取时间相对于数分钟的训练时间而言,差异并不显著。因此在追求最终性能的场景下,计算代价较高的特征仍值得考虑。
| 数据集合 | 特征类型 | 准确率均值 | F1均值 | F1标准差 | 训练时间均值(秒) | 噪声下准确率平均 | 训练时间占总时间比值 |
|---|---|---|---|---|---|---|---|
| 40说话人 | MFCC | 0.715278 | 0.699512 | 0.140234 | 377.6937 | 0.0444 | 0.246856 |
| 40说话人 | Fbank | 0.750694 | 0.73592 | 0.053953 | 402.8998 | 0.1668 | 0.263331 |
| 40说话人 | LPCC | 0.761111 | 0.753095 | 0.079191 | 389.6011 | 0.2179 | 0.254639 |
| 20说话人 | MFCC | 0.747368 | 0.735079 | 0.094648 | 117.6005 | 0.0989 | 0.076862 |
| 20说话人 | Fbank | 0.784211 | 0.779442 | 0.080627 | 128.7725 | 0.2932 | 0.084164 |
| 20说话人 | LPCC | 0.767105 | 0.757327 | 0.056198 | 113.4474 | 0.2482 | 0.074148 |
参考文献
- 戴礼荣,张仕良,黄智颖.基于深度学习的语音识别技术现状与展望[J].数据采集与处理,2017,32(02):221-231.DOI:10.16337/j.1004-9037.2017.02.002.
- 张高峰,刘天,解晓敏,等.基于条件Wasserstein生成对抗网络的说话人辨认研究[J].计算机应用与软件,2025,42(08):213-218+241.
- 郑立通,洪峰,郑婉,等.基于迁移学习和多尺度损失的短语音说话人识别方法[J].声学技术,2025,44(04):565-574.DOI:10.16300/j.cnki.1000-3630.24011601.
- 崔琳,王芷悦. 基于LFBank与FBank混合特征的声纹识别研究[J]. 计算机科学,2022,49(z2):609-613. DOI:10.11896/jsjkx.211000194.
- 余建潮,张瑞林. 基于MFCC和LPCC的说话人识别[J]. 计算机工程与设计,2009,30(5):1189-1191.
- 蔡莲红, 黄德智, 蔡锐. 现代语音技术基础与应用[M]. 北京: 清华大学出版社, 2003.
- 韩纪庆, 张磊, 郑轶然. 语音信号处理[M]. 北京: 清华大学出版社, 2004.
- 宫晓梅,王怀阳. 噪声环境下MFCC特征提取[J]. 微计算机信息,2007,23(22):247-249. DOI:10.3969/j.issn.1008-0570.2007.22.102.
- 丁爱明. 作为说话人识别特征参量的MFCC的提取过程[J]. 电子工程师,2006,32(1):51-53. DOI:10.3969/j.issn.1674-4888.2006.01.017.